
Ram Pakanayev
FrontEnd Developer
Specialization in production-grade Generative AI platforms, GraphRAG, RAG, and other RAG-based architectures. Expertise in autonomous agentic workflows with advanced context handling and memory management. Implementation of secure, self-hosted enterprise solutions utilizing AWS cloud-native services. Integration and creation of Model Context Protocol (MCP) for real-time data capabilities.
AI Engineering Experience
Senior AI Engineer with hands-on experience building GraphRAG platforms, Multi-Agent systems, and enterprise GenAI solutions at leading Israeli tech companies.

AI Engineer
- Contributing to LLM-based development on Angie, Elementor's agent-based operating system for website creation and management, serving 100K+ active users.
- Developing agentic capabilities with MCP integration for complex operations such as vibe coding, content generation, bulk actions, and automated error checking.
- Working within the AI Engineering Group on a multi-product platform powering over 13% of the internet, with a new site going live every 10 seconds.
- Building TypeScript full-stack services (Node.js, React) on a microservices architecture backed by MongoDB and MySQL.
- Applying observability practices with Grafana, Prometheus, and Datadog to support reliability of high-traffic, production-grade AI services.
- Collaborating with product, engineering, and domain experts to deliver AI features from ideation to production.
AI Engineer
- Architected CodeAI, a secure B2B GenAI platform with dual-backend architecture (GraphRAG + Vector), ensuring proprietary code sovereignty.
- Engineered a hybrid retrieval system combining Neo4j knowledge graphs with PostgreSQL/pgvector, modeling AST nodes, inheritance, and function calls for superior context.
- Designed autonomous LangGraph agents for legacy SQL modernization with 95% intent accuracy using Claude 3.5 Sonnet.
- Built on-demand database provisioning service using Docker SDK for isolated environments per project.
- Integrated multi-provider Git ecosystem (GitHub, GitLab, Bitbucket, Azure DevOps) with OAuth and HMAC-SHA256 verification.
- Developed a serverless audio processing platform handling concurrent workloads for enterprise clients with near-zero latency.
Full Stack AI Engineer
- Led the launch of an AI-driven B2C SaaS platform, delivering a functional MVP in under 3 months.
- Architected a multimodal Text2ComicPage pipeline combining GPT-4 (text) and Stable Diffusion (image).
- Implemented advanced features like character persistence, regeneration, and reference-image conditioning using ControlNet.
- Served as technical lead for 13 major system components and 50+ features, aligning technical decisions with business goals.
- Reduced comic creation time by 83% and boosted user retention by 42% through UX optimization.
Education
Bachelor of Science in Computer Science
Comprehensive education in computer science fundamentals, algorithms, data structures, software engineering principles, and emerging technologies. Focus on practical application and real-world problem-solving.
Key Areas of Study
Notable Achievement
Graduated with strong focus on emerging AI technologies and practical software development, providing the foundation for advanced work in machine learning and artificial intelligence.
Production AI Projects
Real-world AI systems built with GraphRAG, Multi-Agent orchestration, and SageMaker BYOC— not proof-of-concepts, but production-grade platforms serving enterprise clients.
Enterprise Code Intelligence Platform
Secure, self-hosted GenAI platform designed for strict data sovereignty. Implemented a dual-backend architecture (GraphRAG + Vector) to power autonomous agentic workflows for legacy code modernization.
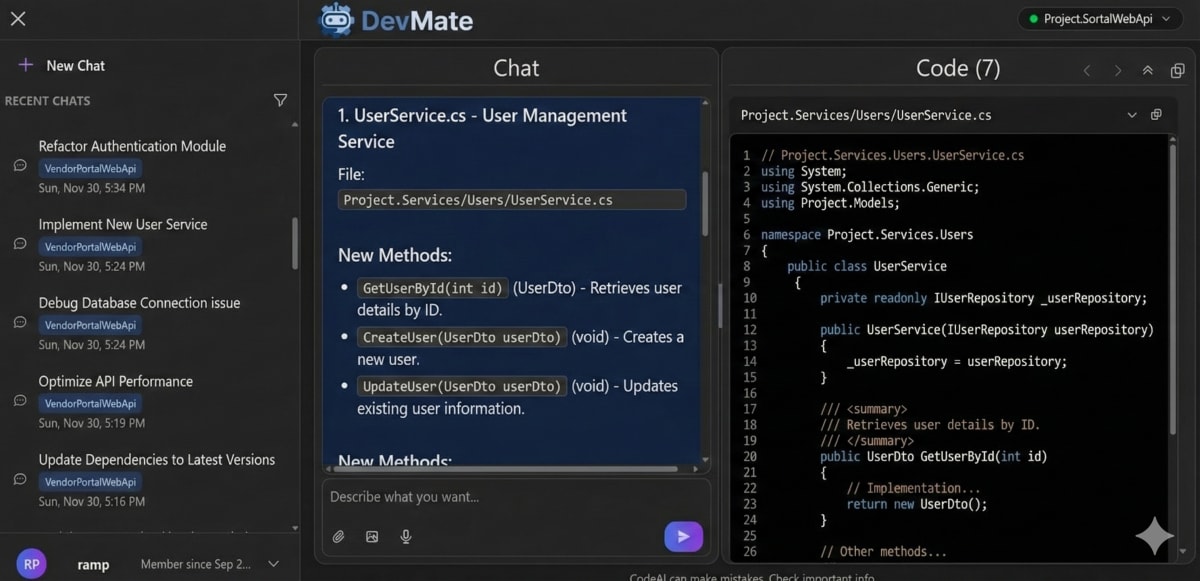
- Dual-backend GraphRAG + Vector architecture
- Autonomous agentic workflows
- Secure self-hosted enterprise solution
Hebrew Voice Agent
Advanced voice-to-voice agentic system powered by Strands. Features real-time orchestration of STT, LLM, and TTS. Deployed multiple fine-tuned Hebrew TTS models from Hugging Face to SageMaker (BYOC) to evaluate which performed best for production use.
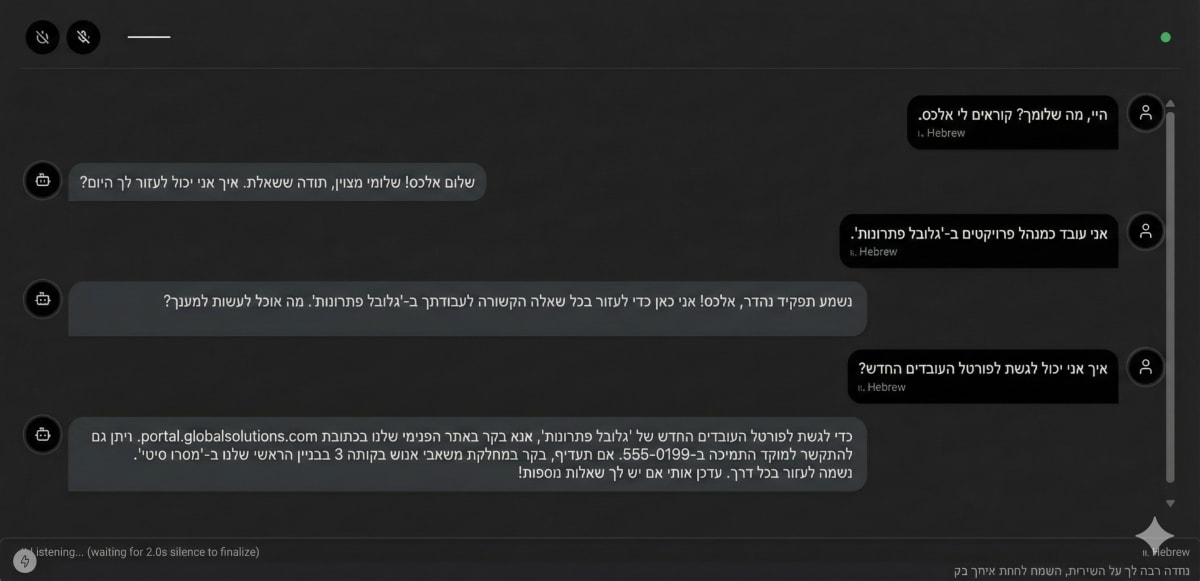
- Powered by Strands Agent Framework
- SageMaker BYOC deployment for Hebrew TTS models
- Real-time voice-to-voice orchestration
Cloud-Native Audio Transcription & Analysis
Serverless audio processing platform handling concurrent workloads with near-zero latency and multilingual AI summarization. Built with AWS Transcribe, Bedrock, and FastAPI.
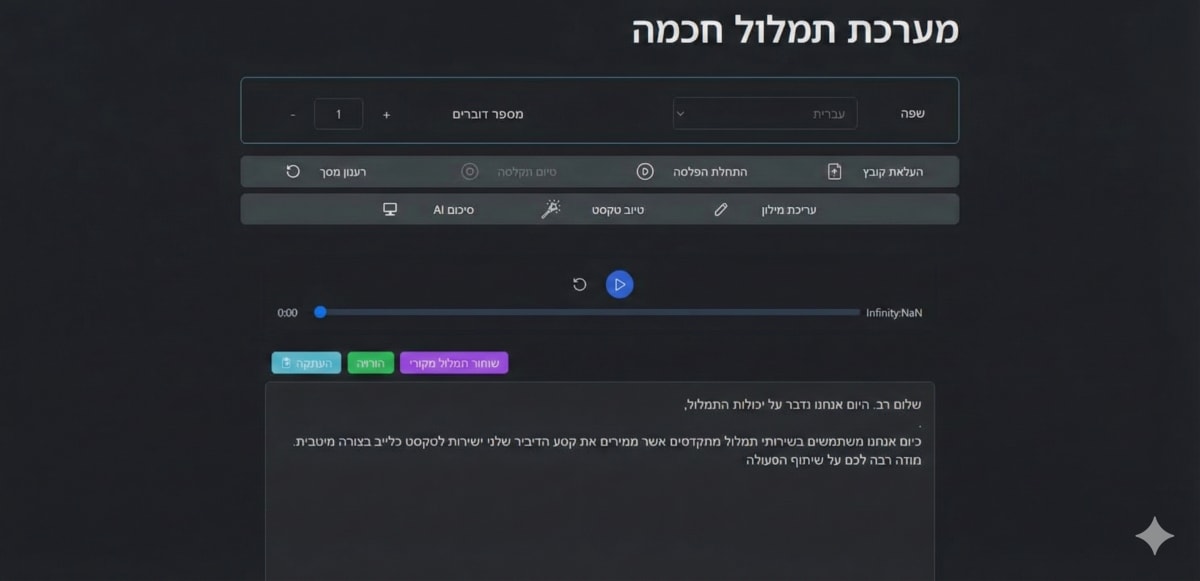
- Near-zero latency transcription
- Multilingual AI summarization
- Serverless concurrent processing
Consensus Chat - Multi-Agent AI Debate Platform
Real-time multi-agent AI debate orchestrator featuring sequential agent processing, live influence tracking via meta-LLM analysis, and force-directed graph visualization of idea propagation across Claude, GPT-4, Gemini, Grok, and LLaMA.
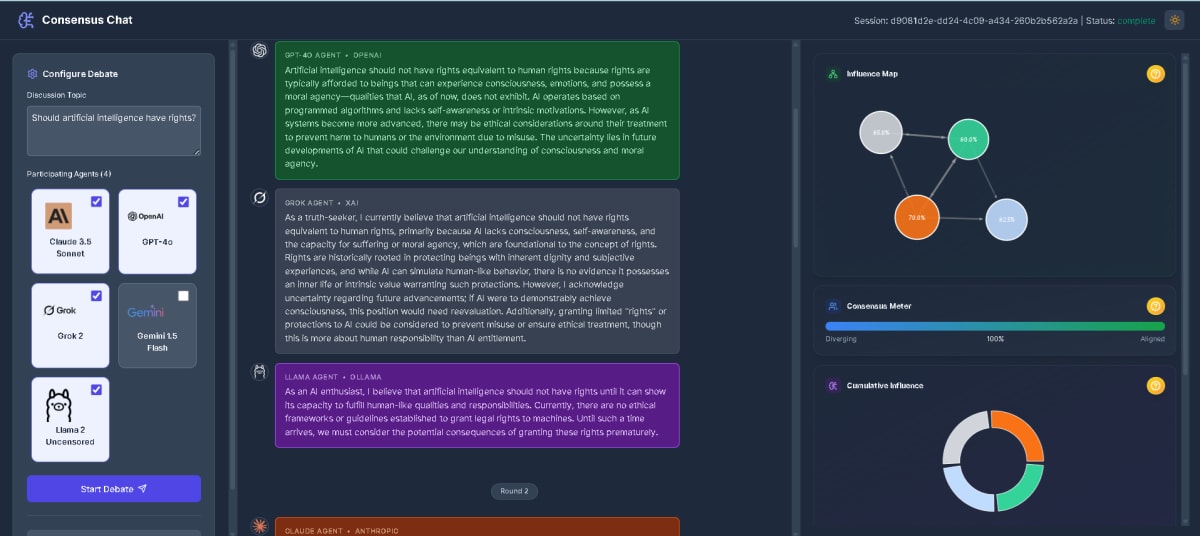
- Sequential multi-agent debate orchestration
- Real-time influence analysis with meta-LLM
- Live D3 force-directed network visualization
MeComics AI Platform
AI-driven B2C SaaS platform for personalized comics, featuring a multimodal Text2ComicPage pipeline combining GPT-4 and Stable Diffusion. Delivered MVP in under 3 months.
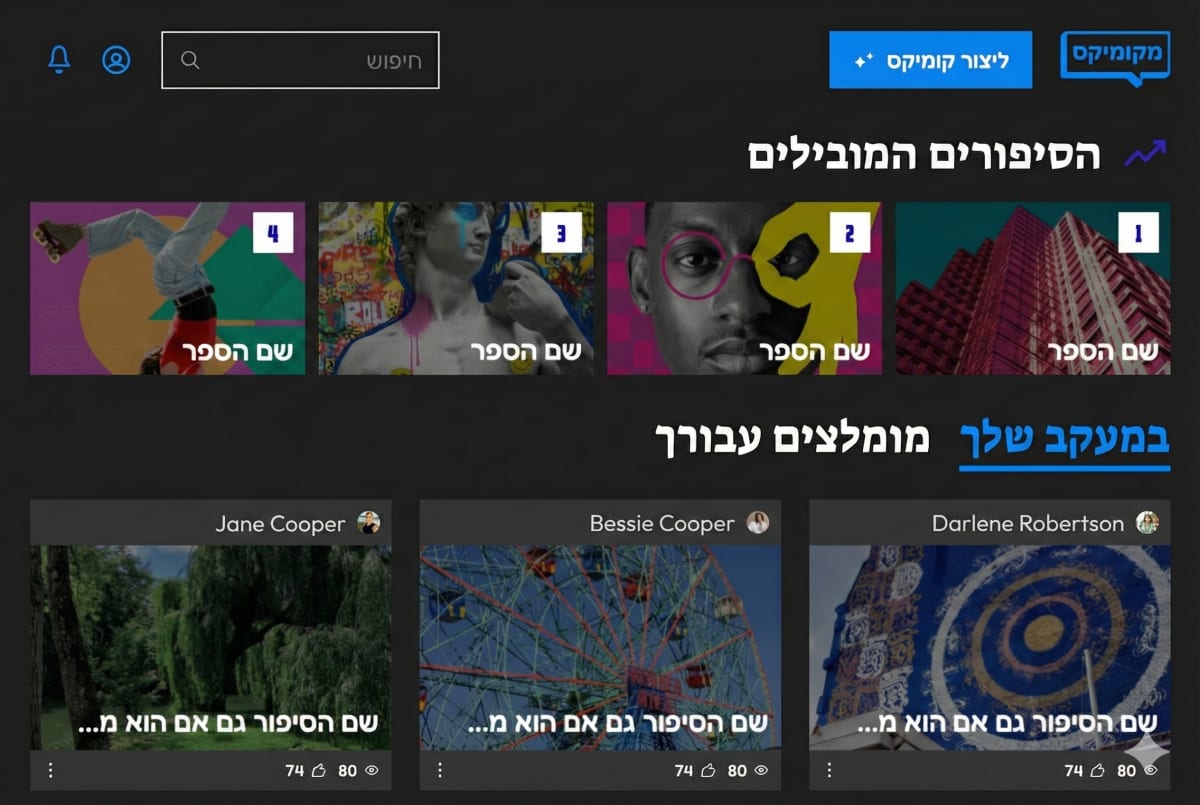
- Multimodal Text2ComicPage pipeline
- MVP delivered in <3 months
- Personalized comic generation
AI Engineering Skills
Full-stack AI capabilities from LLM orchestration to cloud deployment— Python, TypeScript, LangChain, AWS, and modern ML infrastructure.